From flat Notifications to Edge AI
Introduction
For the last few weeks I have been testing the Yazio app, a calorie counter. While using it, I noticed that the notifications — though helpful — were sometimes similar and easy to ignore. This observation sparked a question:
Could these reminders be generated dynamically, on the device, based on my context, and sound more natural or timely?
That question led me into an experiment that sits at the intersection of two emerging technologies: agentic frameworks (JetBrains Koog) and on-device small language models (Google MediaPipe + quantized LLMs). While both exist independently, their integration is still uncharted territory.
The result? A foundational prototype that proves these pieces can work together on Android. This post documents the architecture decisions, integration challenges, what I learned building it and what’s are my next steps.
The problem: Flat notifications
Notification messages are a crucial tool for many apps, and in multiple cases, the main entry point to them. In the case of Yazio, they do a good job reminding users to log meals or water intake.
But after a while, they can start to feel repetitive or disconnected from what’s actually happening in our day. Maybe they arrive when we’re in the gym, or suggest drinking water instead of a cup of tea on a cold day. It’s a natural limitation of static, predefined messages. They don’t adjust to:
- What you’ve already logged
- What time it is
- Your habits or preferences
- Your current activity or mood
In other words, they lack context.
Why Context Matters
Behavioural psychology suggests that timing, tone, and context deeply affect how people respond to messages. Our moms know exactly if we’re hungry, and our favourite dishes for each situation. That’s because they have years and years of context about us (and we trust them! but that’s another topic ☺).
A notification like:
Time for a snack?
vs.
Nice pace today. Since lunch is logged, a quick
summer bite — gazpacho or yogurt with peach — will
keep you moving 💪
It could feel more personal and relevant — not by guessing, but by responding to context. Not quite like your mom, but better than a static reminder.
Hardcoding these messages isn’t scalable, but solving problems of generated language and nondeterministic outputs is exactly where language models shine. So how do we build this context into an app? That’s where agent frameworks come in.
The Solution: Agents + SLM
Building context-aware notifications requires solving two distinct problems:
- Reasoning and orchestration: Deciding when to notify, what context to gather, and how to structure the information
- Natural language generation: Converting that structured context into a human-friendly message
The natural tool choices are agentic frameworks for the reasoning layer and language models for the generation layer:
Using Koog to Emulate an Agent
In case of the Android platform, JetBrains Koog is the valid choice. It’s created in Kotlin and instead of making a raw prompt request, Koog helps implement the following loop:

Koog provides connectors for accessing to data using Model Context Protocol (MCP) and common large language model APIs, orchestrating tools and decisions around a model.
The Edge AI choice
For integrating a model, I believe an hybrid architecture is the best solution: small language models (SLMs) for the default local workflow, with a large model in the cloud as a fallback.
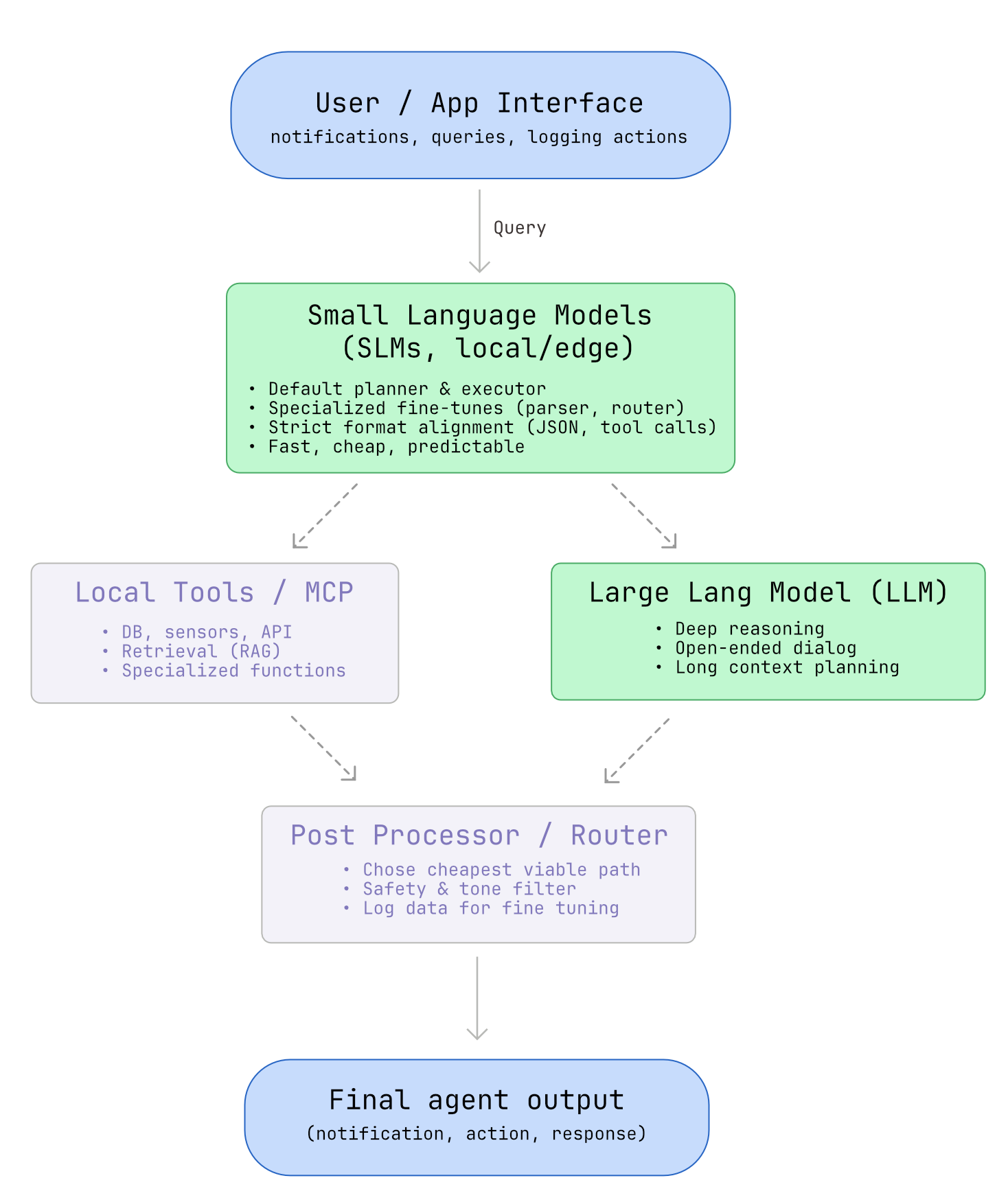
By betting on SLMs now, we will not only reduce costs and latency, but also align with what is likely to become the standard paradigm for reliable, sustainable agentic systems.
For implementing this solution, the Google’s MediaPipe LLM Inference API enables fast, offline calls to a language model directly on Android. In addition, there is a significant list of small models available, and an active community behind them.
The Integration Gap
But here’s the catch: these two worlds haven’t been integrated yet.
- Agentic frameworks assume always-available cloud APIs with instant responses
- On-device inference APIs (like MediaPipe) assume simple request/response patterns with session management
- Koog’s examples use OpenAI/Anthropic/Ollama — none target mobile SLMs
- MediaPipe’s examples focus on standalone inference, not multi-step reasoning
The gap isn’t theoretical—it’s architectural. Session lifecycles, latency profiles, error handling patterns, and resource constraints are fundamentally different between cloud LLMs and on-device SLMs.
This experiment explores whether that gap is bridgeable, and if so, what the integration patterns look like.
Prototype design and implementation
Scope
Currently Implemented:
- Model download and initialization (bundled in repository for simplicity)
- Koog agent structure set up with basic orchestration
- Local inference execution with a hardcoded context example
- Proof that an SLM can generate notification-style text on-device
- Push notifications as the output surface
Not yet implemented (but architected):
- MCP integration for real-time weather/season data
- Safety checks and content filtering
- Remote LLM fallback
- Multi-platform support (iOS)
- User activity tracking and logging
Design
Sequence diagram for the agent orchestration:
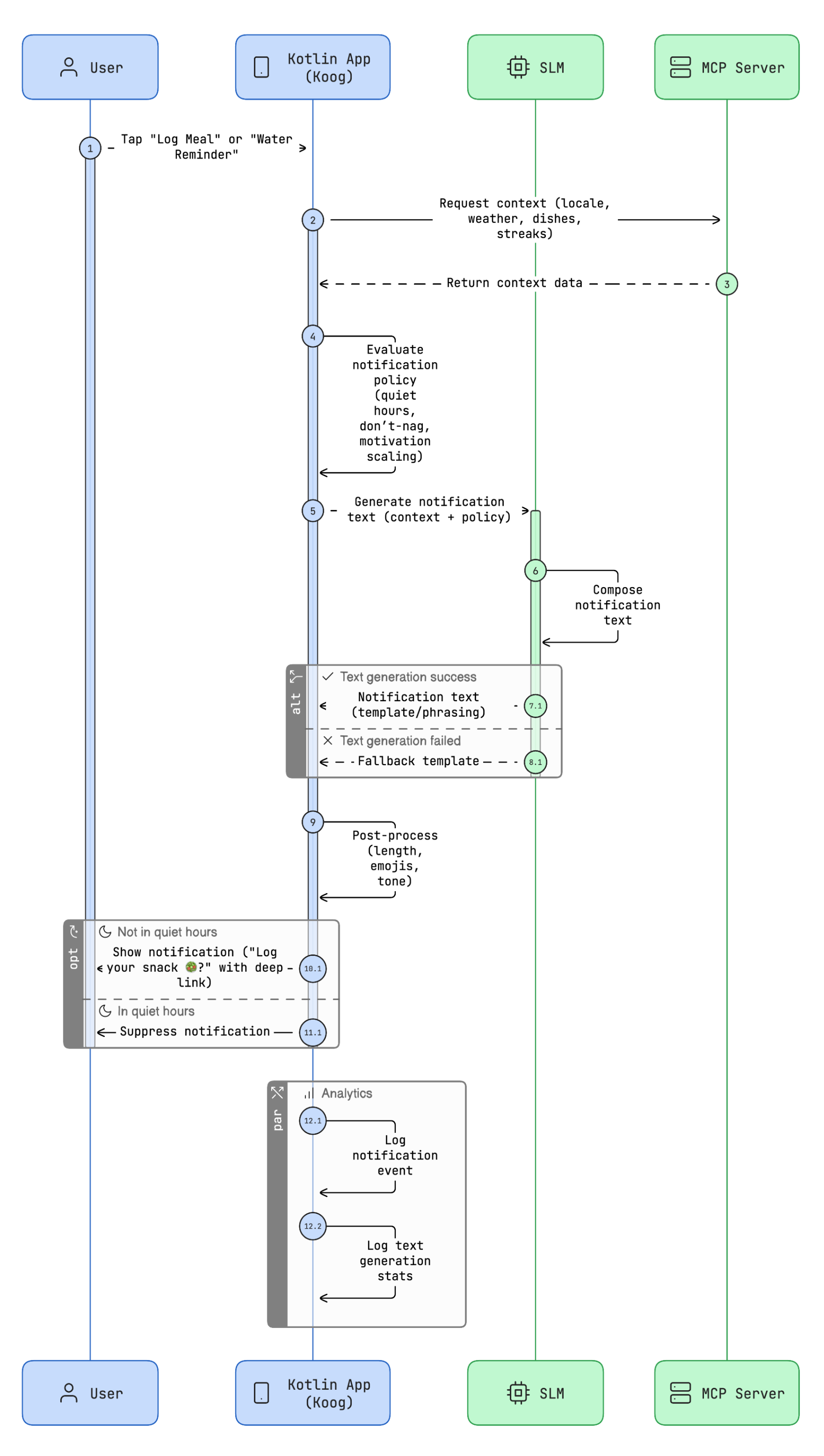
Full diagram source (Mermaid)
Model Choice:
The prototype uses the gemma-3n-E2B-it-litert-lm model from Google. This size balances capability with mobile constraints—small enough to download over WiFi, large enough for coherent text generation.
Model Distribution:
Rather than requiring users to authenticate with HuggingFace or configure API keys, the model is bundled in the GitHub repository as a zip file. This approach prioritizes developer experience for a learning prototype:
- Clone → Build → Run immediately
- No external dependencies or account creation
- Full reproducibility without network calls
- WorkManager for background download
Input DTO example (Koog -> SLM):
userLocale: string (e.g., es-ES)
country: string (e.g., ES)
mealType: enum {BREAKFAST, LUNCH, DINNER, SNACK, WATER}
alreadyLogged: { breakfast: bool, lunch: bool... }
weather: { condition: enum, tempC: number, feelsLikeC: number }
season: enum {WINTER, SPRING, SUMMER, AUTUMN}
localDishes: array of { name: string, mealTypes: enum[], }
motivationLevel: enum {LOW, MEDIUM, HIGH}
Output DTO example (SLM -> Notification):
title: string
body: string
category: string (e.g., “meal_reminder”, “hydration”)
language: string
confidence: number (0–1)
System prompt example:
You are an nutritionist that generates short, motivating
reminders for logging meals or water intake.
User prompt example:
Context:
- Meal type: {mealType}
- Motivation level: {motivationLevel}
- Weather: {weather}
- Already logged: {alreadyLogged}
- Language: {userLocale}
- Country: {country}
Generate a title (max 35 characters) and a body
(max 160 characters) in plain JSON format:
{"title":"...", "body":"...", "language":"en-US",
"confidence":0.9} Use the language and suggest a meal or drink
based on the country provided. {if (alreadyLogged) "- The user
has already logged something today." else "the user has not
logged anything today."}
Implementation
It may sound incredible, but building a simple prototype with a significant part of the requirements described above, is quite straightforward. There is solid documentation from Google and JetBrains with multiple examples. None of them includes local inference but it’s a matter of time that those two worlds converge.
The current implementation contains a simple screen for downloading the model from a static link, changing some parameters and prompting the downloaded model. It demonstrates the notification engine can ‘think locally’ before speaking. The output is a text and a notification message.
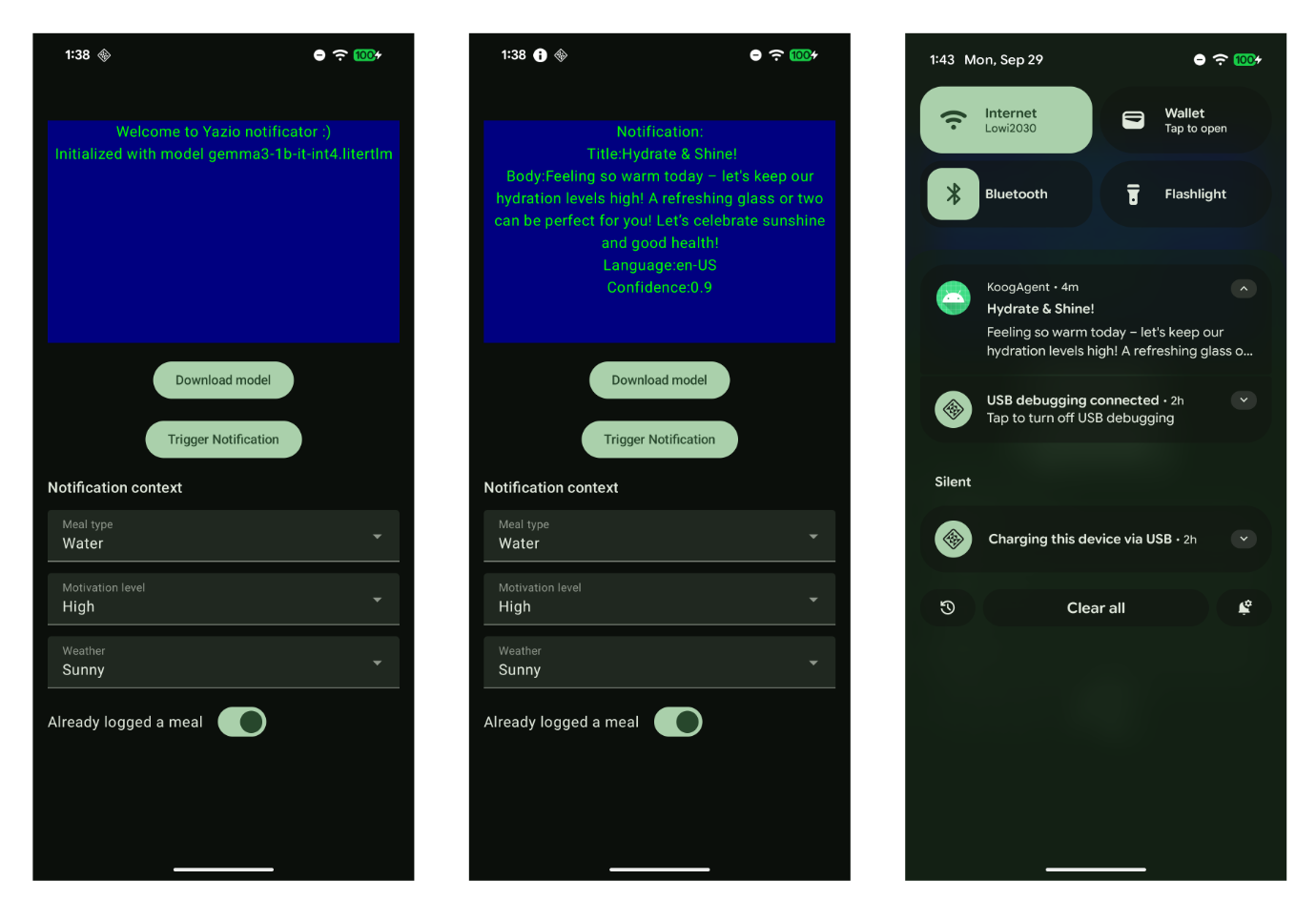
The MediaPipe/Koog Integration
MediaPipe LLM inference is session-based with slow initial loads, typically happening in the background. On the other hand, Koog’s examples assume always-alive remote APIs with sub-second response times.
I have used the following flow to solve this issue:
- Handle async model loading before Koog can invoke it and get a LLM session reference. A practical fix is binding MediaPipe’s session lifecycle to the app’s main activity (or a scoped service).
- Integrates classes from both frameworks using the LLM session
Integration code example (click to expand)
- Manages timeouts and failures gracefully
Reflections & Trade-offs
The Koog framework is overkill… for now: Before using agents, it’s better to find the simplest solution possible, only increasing complexity when needed. Right now Koog’s full orchestration layer is unnecessary overhead. However, this project is a foundation for learning and experimentation. Future versions that incorporate tool calls will justify the additional structure.
The language model, even downloaded in background, is overkill just for pushing better messages: Absolutely. Even downloaded in the background, a 500MB model that consumes 600MB RAM is absurd if only used for push messages. This same model should serve multiple on-device tasks:
- Contextual notifications (this prototype)
- Voice input processing and summarization
- Offline chat or FAQ responses
- Personalized content suggestions
A local dev setup for testing increases the speed: The Ollama + Mistral combination takes 30 seconds to install and provides a local LLM for testing Koog agents and Kotlin pipelines in a pure JVM project.
Privacy and performance is another interesting topic: The system runs inference on-device by default and at this stage, doesn’t send personally identifiable information externally. It could cap the prompt size using compact JSON and caches MCP outputs (like weather or season) to reduce latency and battery usage. Timeouts and fallbacks ensure reliability, and an optional remote model is available only with explicit user opt-in.
Is Multiplatform a good added value?: Not in the first stage of the prototype. Although the Koog related classes are in a separate module, I consider it’s better to invest efforts experimenting with the agentic structure and add the local inference in iOS once the Android side is ready and tested.
Testing and Evaluation:
Thinking in product managers, the whole feature can be tested using the following approach:
-
A small but representative “golden set” of 50 context scenarios (combining meal type, time, weather, region, and dietary tags) to verify the system responds appropriately across typical edge cases.
-
Linguistic checks — length, emoji count, locale, forbidden words, and sensitive claims — to ensure messages are safe, readable, and culturally consistent.
-
For impact, A/B test template-based notifications versus LLM-generated ones, measuring tap-through (CTR) and time-to-log to confirm real user benefit.
-
Finally, we could enforce an end-to-end latency budget of roughly 250–600 ms on mid-range devices, quantized ~1B SLM, short prompts, and constrained decoding; if the pipeline exceeds that threshold, it will fall back to deterministic templates to preserve UX reliability.
Current state: These metrics are hypothetical. The prototype doesn’t yet collect telemetry or implement A/B testing infrastructure. This section documents how I would evaluate the system in production.
Conclusions
This integration represents a path toward sustainable, privacy-preserving agentic AI. Instead of sending every user interaction to cloud LLMs, we can reason and generate locally for routine tasks—reserving expensive cloud calls for truly complex problems.
The prototype is incomplete and over-engineered for its current capabilities. But it proves the foundation exists.
What is Next?
- Real context integration — Connect MCP servers for weather, season, and local dish data instead of hardcoded examples
- Prompt refinement — Iterate on prompt structure based on output quality
- Safety layer — Implement post-processing checks before notification delivery
- Remote fallback — Add cloud LLM fallback with explicit user opt-in for complex scenarios
- Performance profiling — Comprehensive benchmarking across device tiers and Android versions